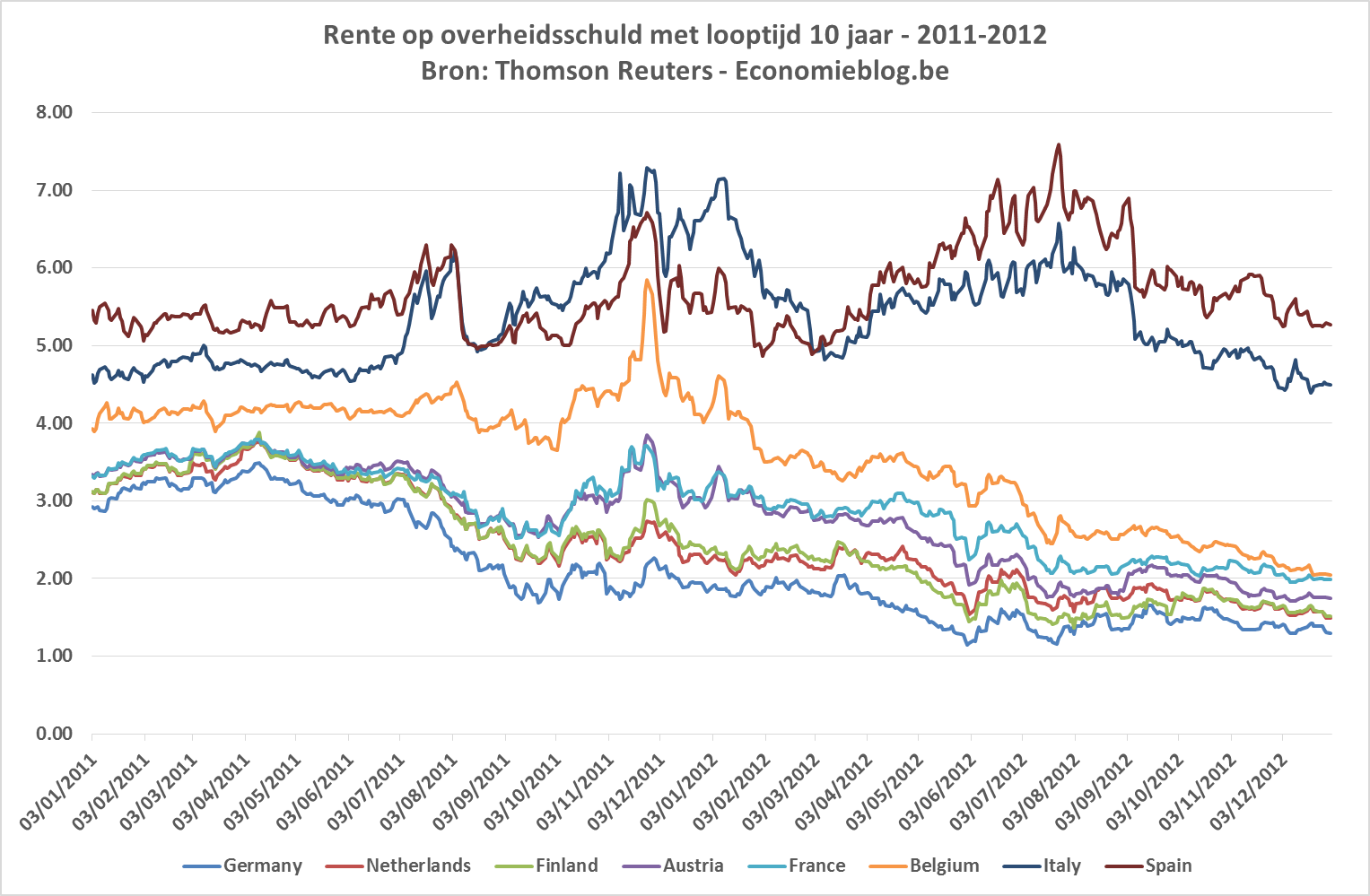
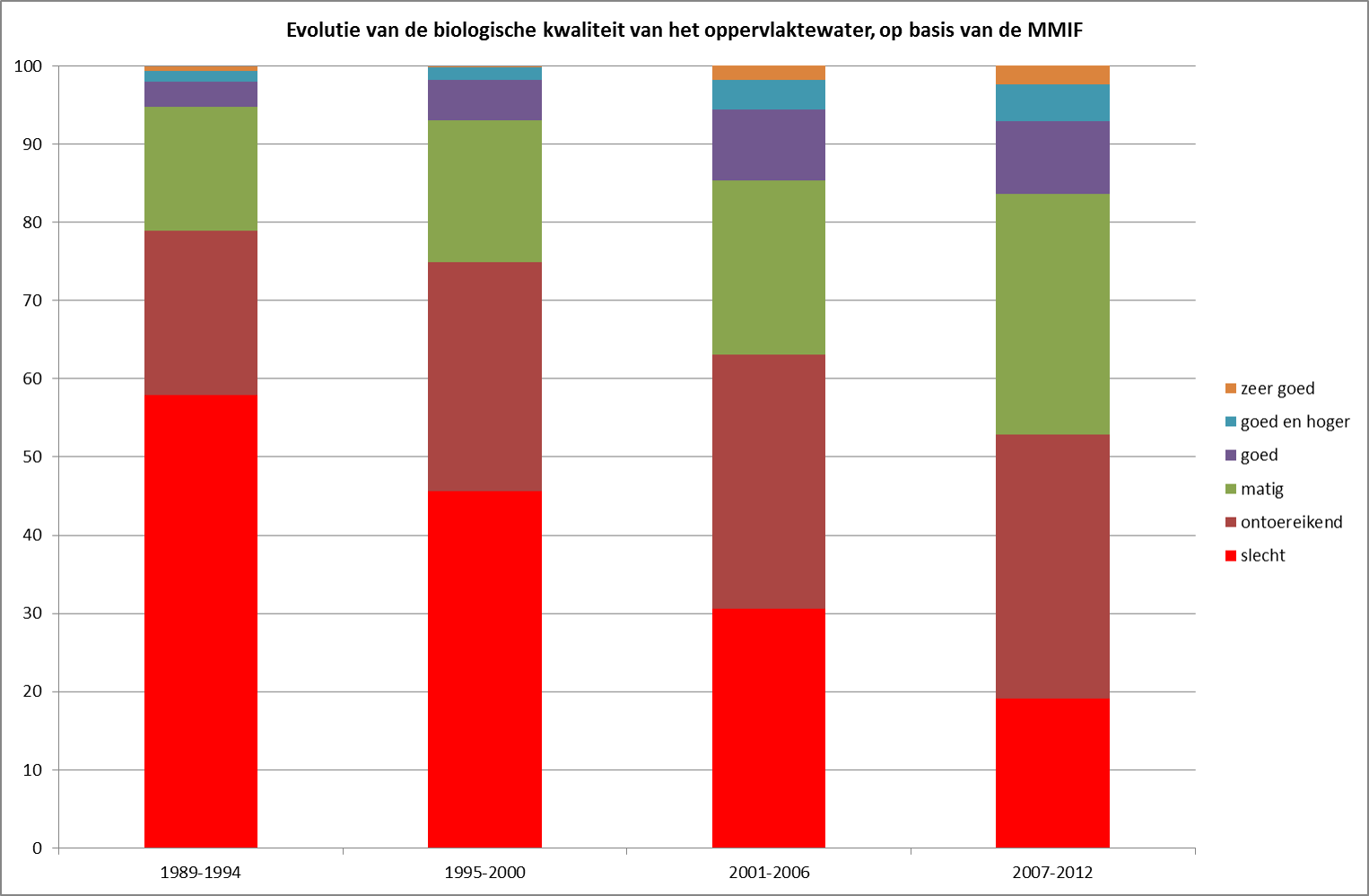
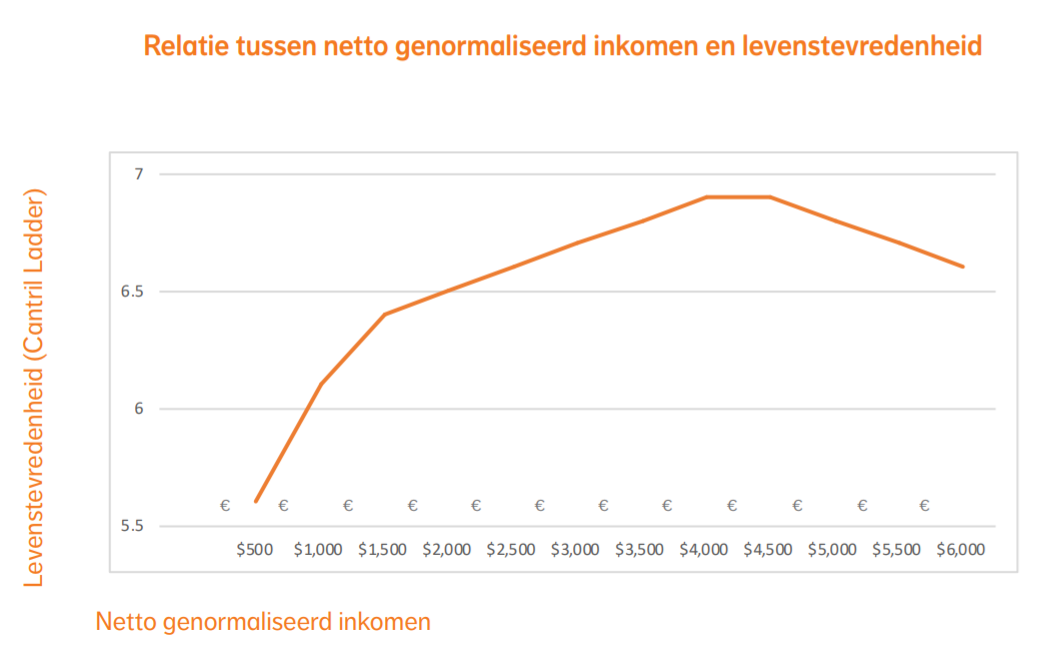
Een paar weken geleden publiceerden de UGent en levensverzekeraar NN een nieuw luik van hun Nationaal Geluksonderzoek. De blikvanger was deze keer dat meer geld wel degelijk gelukkiger maakt, maar slechts tot een bepaald niveau. Vanaf een maandinkomen van 4000 euro wordt de Belg gemiddeld niet gelukkiger meer. Meer nog, vanaf 5000 euro en meer zou de Belg gemiddeld ongelukkiger worden. De onderstaande grafiek komt uit het persdossier van het onderzoeksteam.
Het is wellicht onnodig te zeggen dat de afname van geluk voor de hoge inkomens veruit de meeste media-aandacht trok. Voor professor Annemans (UGent), betrokken bij het onderzoek, bewijzen de cijfers dat we het economisch systeem moeten herdenken om het geluksniveau op te krikken.
Dat er een verzadingspunt en zelfs een terugval is, vind je ook terug in ander, internationaal onderzoek. Een artikel van uit Nature Human Behaviour (‘Happiness, income satiation and turning points’) van begin dit jaar kwam tot eenzelfde resultaat. In het artikel stellen de auteurs dat er een verzadigingspunt optreedt op 95.000 dollar per jaar wat betreft levenstevredenheid. Wat betreft emotioneel welzijn ligt het verzadigingspunt tussen 60.000 en 75.000 dollar. Nochtans, zo stellen de auteurs, zijn er andere onderzoeken die geen verzadiging of terugval vaststellen. De wetenschap is er dus nog niet uit.
In het artikel uit Nature Human Behaviour worden er een aantal redenen opgesomd waarom vorige studies die concludeerden dat er een verzadigingspunt is belangrijke beperkingen hadden. Zo gebruikte een belangrijke studie categorische variabelen voor de inkomens. Een andere beperking is de bron van data: gegevens uit bevragingen zijn minder betrouwbaar dan uit een fiscale inkomensdatabank.
Gebrek aan data
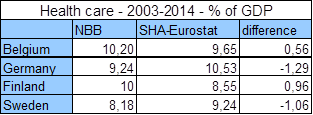
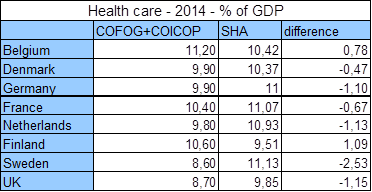
Ten slotte is er het gebrek aan data, waardoor sommige studies geen uitspraak kunnen doen over het feit of er een verzadiginspunt is in de relatie tussen inkomen en geluk. Dat komt omdat het verzadigingspunt erg hoog ligt. Dat geldt ook voor de Belgische studie. De geciteerde inkomens uit die studie zijn immers netto-inkomens en zijn genormaliseerd, wat wil zeggen dat ze rekening houden met het aantal volwassenen en kinderen per gezin. Een genormaliseerd netto maandinkomen van 4500 euro komt dan overeen met een netto inkomen van 9450 euro voor een koppel met twee kinderen. Met een dergelijk hoog inkomen zit je makkelijk in de top 1%.
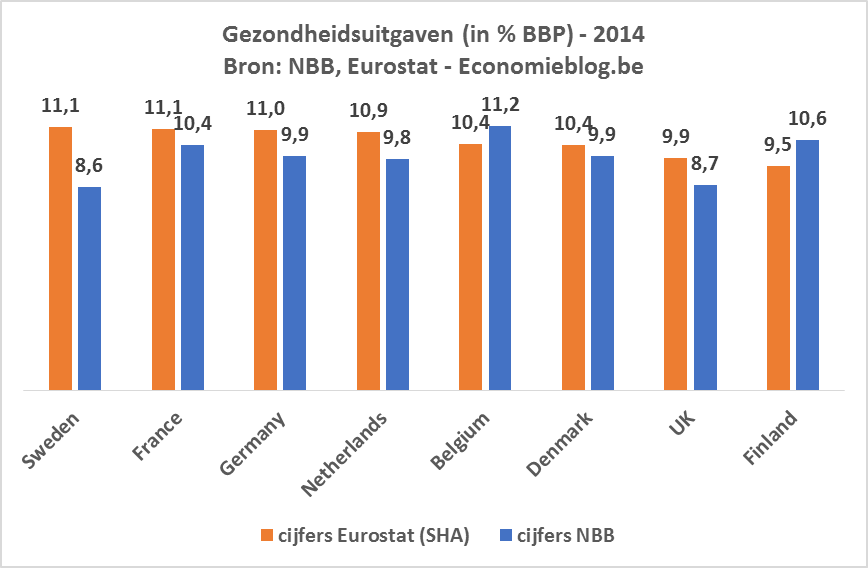
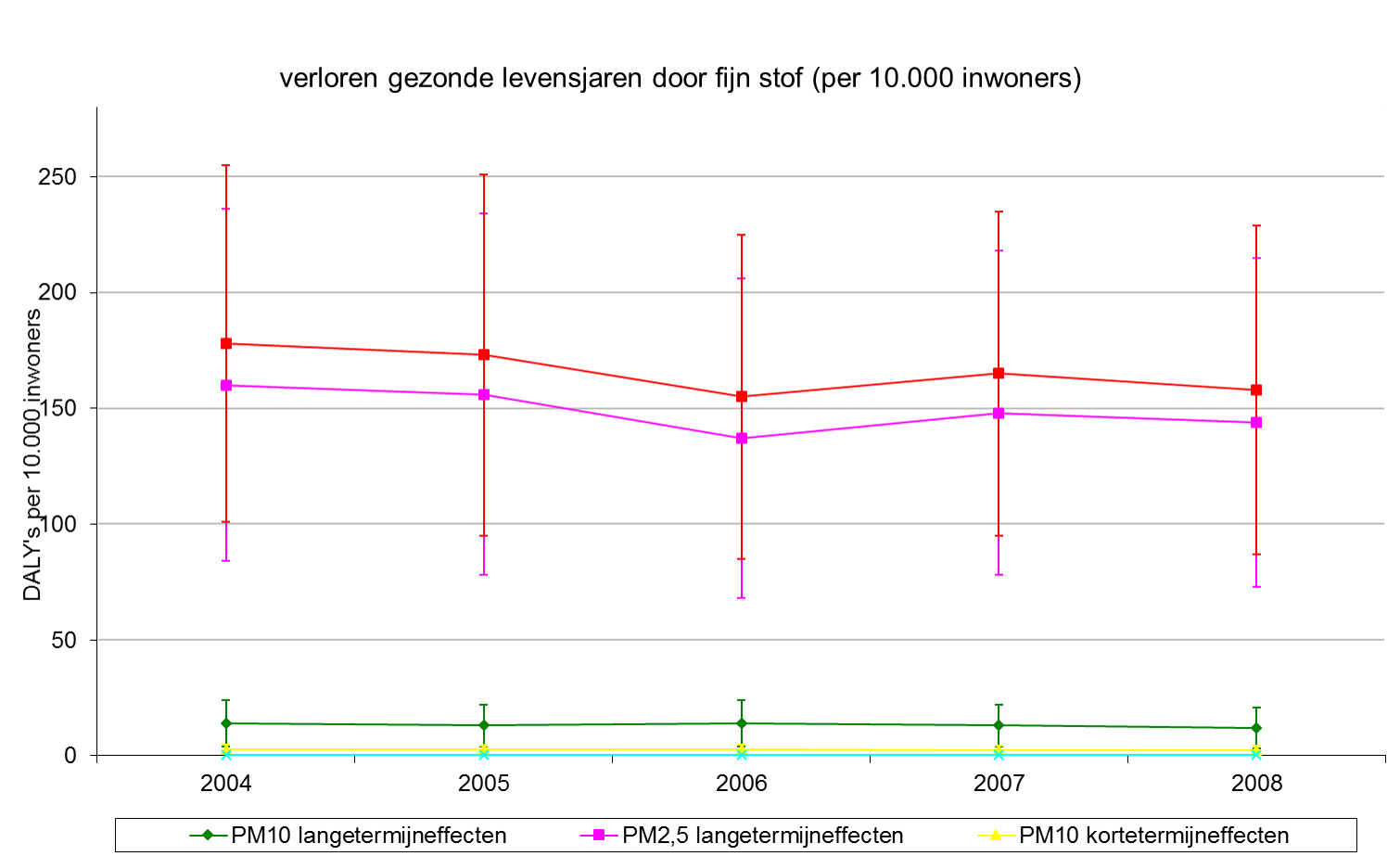
En die top 1% participeert niet makkelijk in allerhande onderzoeken die ook peilen naar het inkomen. In het persdossier zat de onderstaande grafiek met daarin het percentage van de 3770 respondenten per inkomenscategorie: uit deze grafiek blijkt dat het aantal respondenten al afneemt voor inkomens vanaf 2500 euro.
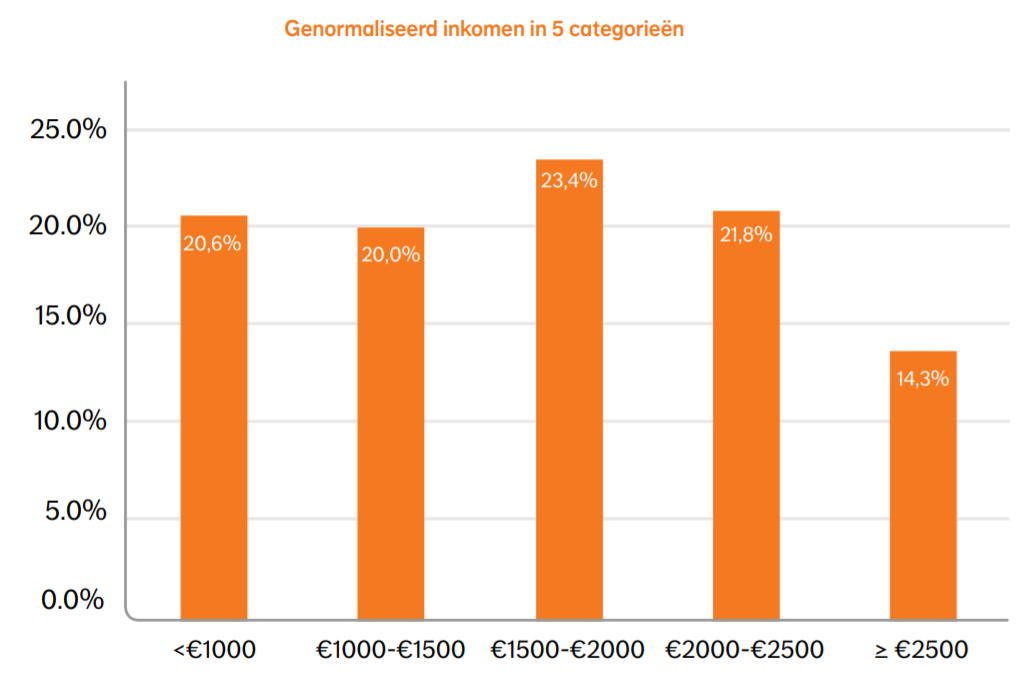
Het is opmerkelijk dat deze slechts gegevens geeft tot 2.500 euro, terwijl de blikvanger van het onderzoek gaat over wat er gebeurt vanaf 5.000 euro; dat is precies het dubbele. Ik heb de data dan opgevraagd bij de persverantwoordelijke van het onderzoeksteam en zij gaf me de onderstaande grafiek mee.
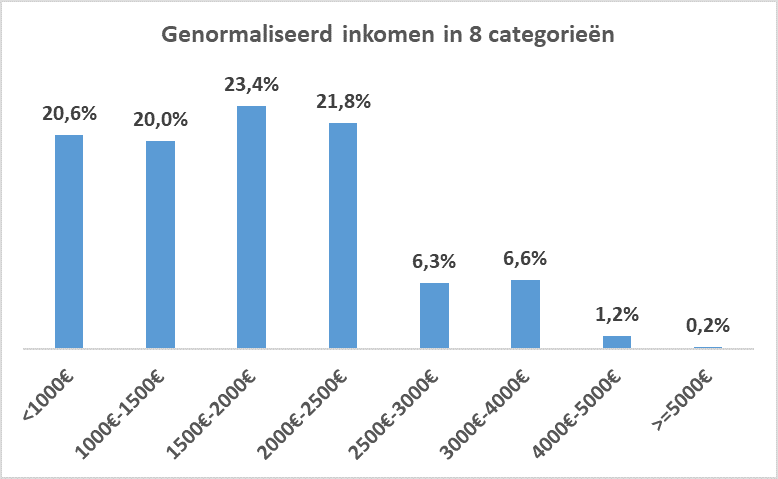
Uit deze grafiek blijkt dat ook in dit onderzoek het niet goed gelukt is om voldoende respondenten te vinden in de inkomenscategorie waar het om draait, wanneer men een goed gefundeerde uitspraak wil over het al dan niet bestaan van een verzadigingspunt. Van de 3770 Belgen die aan het onderzoek deelnamen, had slechts 0.2% een genormaliseerd inkomen van 5000 euro of meer. Het gaat dus over 6 tot 9 personen op 3770. De opmerkelijke conclusie van het onderzoek dat een netto-inkomen van 5000 euro of meer ongelukkiger maakt lijkt dan ook op los zand gebouwd.
Bijkomende informatie over het onderzoek
Het bovenstaande had ik ook in een opiniestuk geschreven op vraag van De Morgen. De dag erna was er een reactie van professor Annemans die onder meer inging op het zeer beperkt aantal respondenten. Hij schreef het volgende: “Bij zo’n analyse dragen álle deelnemers bij aan het eindresultaat. Stel u voor dat de bevinding, met name dat de levenstevredenheid opnieuw licht daalt bij de hoogste inkomens, gebaseerd zou zijn op slechts een handvol waarnemingen, zoals Andreas suggereert. Onze analyses steunen op honderden, zelfs duizenden waarnemingen. Het gevonden verband was bovendien statistisch uiterst significant.”
Gezien deze uitspraken me nog nieuwsgieriger maakten naar de gebruikte methode nam ik contact op met professor Annemans met een aantal vragen. Uit zijn antwoord bleek dat de gegevens verzameld zijn door middel van een bevraging, waarbij de respondenten moesten aangeven in welke inkomenscategorie hun gezin zich bevindt (met intervallen van 500 euro). Deze inkomens werden vervolgens genormaliseerd volgens gezinssamenstelling.
De professor schreef ook dat de eigenlijke analyse gebaseerd is op een multivariate regressie, corrigerend voor o.a. leeftijd, geslacht, opleidingsniveau,… waarbij zoals in ander onderzoek de inkomensvariabele ook wordt gekwadrateerd om na te gaan of er inderdaad een kwadratische relatie is. De kwadratische term in de analyse was zeer significant (p-waarde 0.00003), aldus de professor.
Dat riep bij mij weer een aantal bijkomende vragen op. De professor verwijst naar een kwadratische term in de multivariate regressie. Dat betekent echter niet meer dan dat er getest wordt of het inkomen een andere dan een constante, proportionele relatie met levenstevredenheid heeft (in jargon: is de relatie lineair of niet). Uit ander onderzoek weten we immers dat de levenstevredenheid inderdaad stijgt met het inkomen, maar dat die stijging niet in dezelfde mate blijft toenemen, naarmate men een hoger inkomen heeft. Er is dus geen constant stijgende levenstevredenheid naarmate het inkomen toeneemt (het verband is niet lineair).
Om een rekenvoorbeeld te geven: stel dat we vaststellen dat als het inkomen van 2000 naar 2500 euro stijgt, de levenstevredenheid gemiddeld gezien stijgt van 6 naar 6.5. Dat betekent dat een stijging van 500 euro leidt tot een stijging van 0.5 punt op de schaal van de levenstevredenheid. De vraag is dan in welke mate de levenstevredenheid stijgt als het inkomen verder stijgt van 2500 naar 3000 euro en verder naar 3500, 4000,…. Als de levenstevredenheid dan ook stijgt van 6.5 naar 7, en verder naar 7.5, 8,… dan kunnen we stellen dat de relatie tussen inkomen en levenstevredenheid proportioneel (lineair) is. De proporties van de stijging met het inkomen zijn immers gelijk.
Echter, dit is niet wat wordt vastgesteld. Naarmate het inkomen stijgt, stijgt de levenstevredenheid wel nog, maar in mindere mate. Het verband is dus niet proportioneel (lineair) maar iets anders. Om na te gaan of iets wel of niet lineair is kan men een kwadratische term toevoegen.
Als de coëfficiënt bij deze kwadratische term significant is (en in dit geval moet deze negatief zijn om te wijzen op de afnemende stijgingen), dan mag je inderdaad concluderen dat de relatie niet lineair is. Deze statistische significantie geeft dan uitsluitsel dat een kwadratische verband beter is dan een lineaire verband om het verband tussen inkomen en levenstevredenheid weer te geven.
Maar er zijn nog veel andere manieren om te testen of het verband lineair is of niet. Een kwadratische term toevoegen is er maar één van. Zo wordt in dit type onderzoek vaak ook een logaritmisch verband getest. In deze discussie is dat geen wiskundige haarkloverij, maar essentieel. Een kwadratisch verband met een negatief teken bij de kwadratisch term stelt een omgekeerde parabool voor. Dat betekent dat een kwadratisch verband stelt dat de levenstevredenheid bij hogere inkomens terug afneemt, na een maximum bereikt te hebben (= de top van de omgekeerde parabool). De logaritmische functie kent echter geen maximum: die blijft doorstijgen.
De blauwe lijn op de onderstaande figuur toont een kwadratische functie, waarbij het maximum zich op x=3 bevindt. De oranje lijn geeft de logaritmische functie. Deze lijn stijgt in het begin sneller dan op het einde, maar kent geen maximum. De lijn blijft doorstijgen, zij het heel traag.
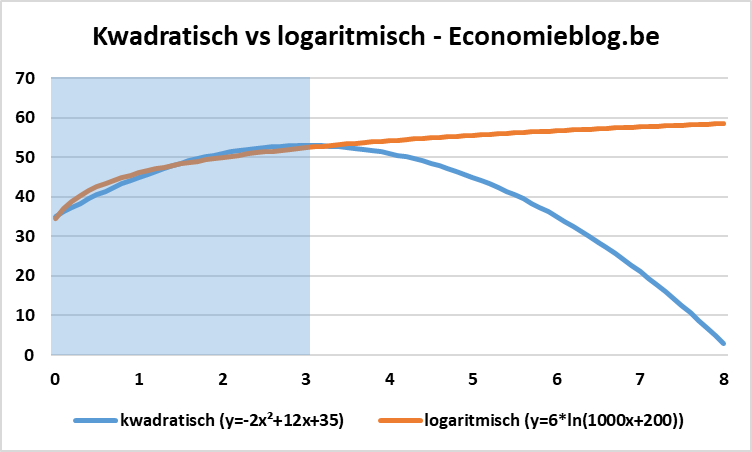
Een logaritmisch verband geeft dus ook aan dat het verband tussen inkomen en levenstevredenheid niet lineair is (de stijging neemt af bij hogere inkomens), maar waar bij een kwadratisch verband de levenstevredenheid uiteindelijk terug moet afnemen, is dat niet het geval bij een logaritmisch verband. Bij een logaritmisch verband blijft de levenstevredenheid stijgen bij hogere inkomens, hoewel de stijging (veel) minder snel gaat dan bij lagere inkomens. En dat is net de conclusie van een ander onderzoek, van Stevenson en Wolfers uit 2013, namelijk dat er een logaritmische relatie is tussen inkomen en welzijn (“well-being”). De fout die in het Belgische onderzoek dan ook gemaakt is, is dat er op voorhand een bepaalde functionele vorm gekozen is, namelijk een kwadratische functie.
Als je bovenstaande grafiek bekijkt, dan lijkt het bijna onmogelijk dat je je kan vergissen tussen een kwadratisch of logaritmisch verband, omdat het verschil aan de rechterkant van de grafiek overduidelijk wordt. Maar dat verschil is er nagenoeg niet als je enkel de linkerkant van de grafiek bekijkt, met name het gedeelte met de blauwe achtergrond (tot x=3). Dan lijken de logaritmische en kwadratische functie sterk op elkaar.
En dat is net wat er aan de hand is met de gegevens van professor Annemans. In zijn onderzoek vallen bijna alle gegevens in het blauwe gedeelte. De maximale levenstevredenheid wordt immers pas bereikt tussen 4000 en 5000 euro, daarna zou deze afnemen. Maar daarna zijn er slechts een handvol gegevens. Als je enkel een kwadratische functie test met 99,8% van je gegevens die op of vóór het maximum van de kwadratische functie liggen, gelijkaardig aan de blauwe zone in de bovenstaande figuur, dan kan je geen uitsluitsel geven of het nu een kwadratisch of een logaritmisch verband is. Wil je dat wel kunnen, dan moet je veel meer gegevens hebben na de blauwe zone (en boven 5000 euro). Heb je die gegevens niet, dan kan je daar geen uitspraak over doen.
Ik heb deze analyse aan professor Annemans voorgelegd en hij erkende dat ze te snel gekozen hadden voor de kwadratische functie en dat ze ook de logaritmische relatie hadden moeten testen. Hij erkende dan ook dat ze de conclusie niet hadden mogen trekken dat levenstevredenheid afneemt bij hoge inkomens.
Op dat punt zijn we het dus eens en zou en het is belangrijk dat professor Annemans dit erkent. Hij stelde echter dat er geen gebrek aan data is om deze conclusie eventueel te kunnen trekken; er moet gewoon ook nog eens getest worden of de logaritmische functie beter is dan de kwadratische functie. Dat is volgens mij opnieuw een sterk betwijfelbare stelling. Meer nog, ik durf nu al te zeggen dat de data voor de zeer hoge inkomens veel te beperkt zijn om op een wetenschappelijk zinvolle manier uitsluitsel te geven tussen een logaritmische en kwadratische functie. Ik schat dat er immers maar 6 tot 9 datapunten in de inkomenscategorie van 5.000 euro en hoger zitten. Deze zullen geen statistische significante keuze kunnen maken tussen de kwadratische en de logaritmische functie. De enige wetenschappelijk aanvaarde conclusie moet zijn dat we op basis van de gegevens van professor Annemans niet kunnen weten of levenstevredenheid afneemt bij zeer hoge inkomens. Die conclusie is uiteraard minder sexy dan te kunnen stellen dat levenstevredenheid afneemt voor de hoogste inkomens, maar wetenschap is nu eenmaal niet altijd sexy (voor de media).
Tenzij ik iets over het hoofd zie, moet dit dan ook rechtgezet worden.
Meer uitleg over de kwadratische en logaritmische functies en een aantal simulaties vind je onderaan deze tekst.
Meer objectiviteit in plaats van meer subjectiviteit
Dat neemt niet weg dat de conclusie juist kán zijn dat de levenstevredenheid afneemt vanaf een zeer hoge inkomen. Maar zelfs als die conclusie correct zou zijn, dan nog is dat geen reden om ons economisch systeem te herdenken om het gelukniveau op te krikken. De reden is eenvoudig: geluk is subjectief. Er zijn mensen te vinden die arm zijn, maar veel gelukkiger dan de rijkeluiszoon die doodongelukkig is omdat hij geen Porsche kreeg voor zijn achttiende verjaardag. Om het geluksniveau dan op te krikken, zou je de arme meer moeten belasten om de Porsche van de rijke te betalen.
Het is een voorbeeld dat geïnspireerd is op het bekende artikel ‘Equality of What?’ van Amartya Sen uit 1979. Sen stelde zich de vraag wat we nu eigenlijk gelijk willen. Hij kwam tot de conclusie dat het niet om geluk (of nut) gaat. Sen stelde dat waar het om draait, is of mensen de mogelijkheid hebben om het goede leven te leiden. Daarvoor heb je een aantal basiscapaciteiten of -functies nodig. En die zaken kan je min of meer objectief vaststellen (hoewel ze in de tijd en tussen landen kunnen verschillen). Het gaat om basisbehoeften zoals voeding, wonen en veiligheid, maar ook over kunnen lezen en schrijven, politiek kunnen deelnemen en, in een maatschappij als de onze, toegang tot internet. Voor Sen is het duidelijk dat een maatschappij pas rechtvaardig is als deze objectieve noden voor elke mens vervuld kunnen worden. Of elke mens er ook daadwerkelijk gelukkig van wordt, is niet de verantwoordelijkheid van de maatschappij, maar van het individu zelf.
Tot slot, er is een andere reden waarom we hoge inkomens meer moeten belasten en lage inkomens minder. Er zijn drie oorzaken waarom mensen rijk zijn en die meestal samen in het spel zijn: erg rijke mensen werken vaak hard, hebben vaak ook veel talent en hebben ook gewoon geluk. Aan die twee laatste factoren heeft de rijke zelf geen verdienste, en daarom is het moreel aanvaardbaar dat we hogere inkomens meer belasten. Maar ook weer niet teveel, of rijke mensen gaan minder hard werken, waardoor je minder kan belasten en herverdelen. Er is dus ergens een optimum. Waar dit optimum ligt, is volgens mij een vraag voor de econoom die zich bezig houdt met de theorie van de optimale belastingstructuur. Voor het herdenken van ons economisch systeem hebben we dus eerder een ‘belastingseconoom’ dan een ‘gelukseconoom’.
BIJLAGE
Enkele simulaties over het kwadratische of logaritmische verband tussen levenstevredenheid en inkomen
De onderstaande figuur simuleert de relatie tussen inkomen en levenstevredenheid, gegeven dat de laatste 7 datapunten (vanaf 5000 euro) effectief een dalende levenstevredenheid vertonen. In de simulatie is dan rekening gehouden met het aantal datapunten dat er beschikbaar was voor elk inkomensinterval. Het resultaat staat in de onderstaande figuur. Voor 500 euro gaat het om 777 datapunten, voor 1000 euro gaat het om 754, enzovoort. Voor 5000 euro gaat het om 3 datapunten, voor 5500 om 2 datapunten en voor 6000 of meer ook 2 datapunten. Ik heb wat ruis op de datapunten gezet.
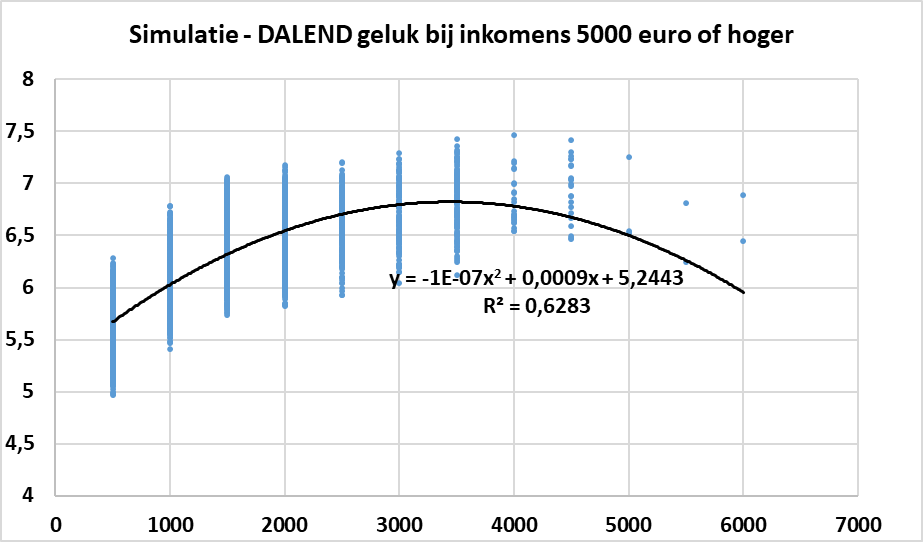
Wanneer er een regressieanalyse wordt uitgevoerd op deze datapunten met als verklarende variabelen voor de levenstevredenheid het inkomen en het inkomen in het kwadraat, dan blijkt dat de coëfficiënt van de kwadratische term negatief is en dat dit resultaat zeer significant is.
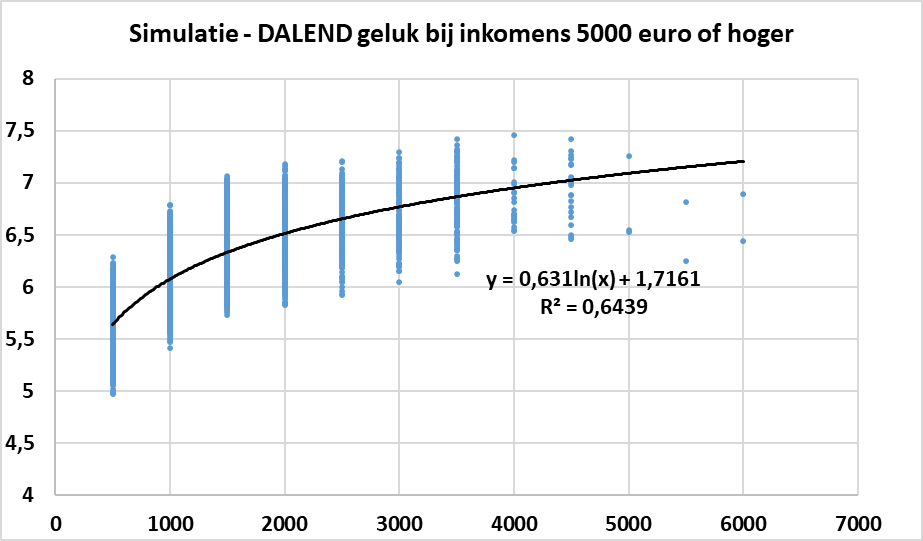
Je kan op dezelfde data echter ook een logaritmische relatie testen. De coëfficiënt bij de verklarende variabele is positief en ook dit resultaat is zeer significant (met p-waarde = 0). Bovendien blijkt de verklarende kracht van deze functionele vorm zelfs hoger te zijn: de R² voor een logaritmische relatie is 0.644 tegenover 0.628 bij de kwadratische vorm. Dit zou opmerkelijk moeten zijn, omdat we in deze simulatie aannemen dat de levenstevredenheid afneemt bij zeer hoge inkomens. Maar de 3300 datapunten tot 4000 euro volgen eerder een logaritmische functie en overstemmen de 7-8 datapunten van 5000 euro en hoger.
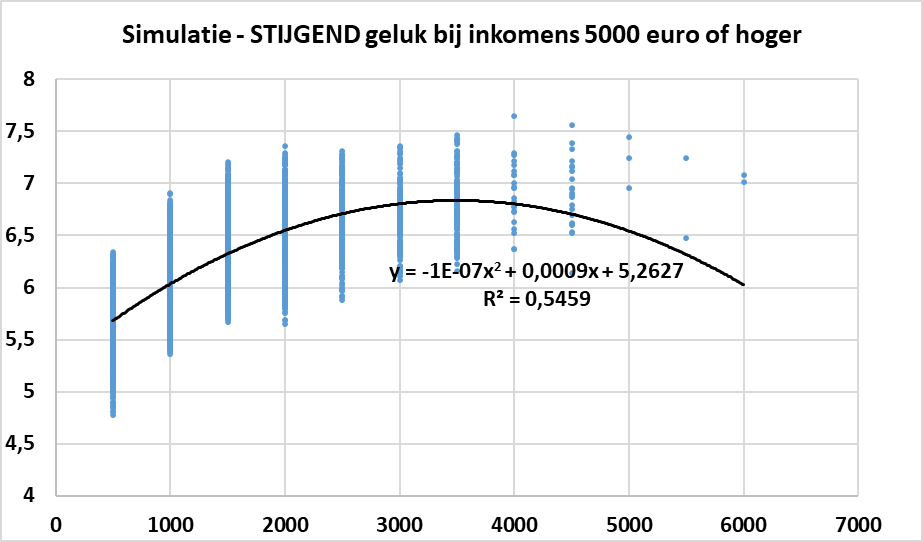
Ik heb ook eens dezelfde simulatie gedaan, maar voor de laatste 7 datapunten (vanaf 5000 euro) heb ik een stijging gesimuleerd: in deze wereld blijft de levenstevredenheid stijgen, ook bij grote inkomens. Met een regressieanalyse met de kwadratische vorm bekom ik opnieuw dat de coëfficiënt bij de kwadratische term significant negatief is.
Deze simulatie toont onweerlegbaar aan dat de conclusie die professor Annemans trekt niet kan getrokken worden op basis van zijn gegevens. De simulatie toont immers dat zelfs bij een sterk stijgende levenstevredenheid, ook bij zeer hoge inkomens, de conclusie van de statistische analyse is dat de coëfficiënt bij de kwadratische term negatief is, en dat dit zeer significant is.
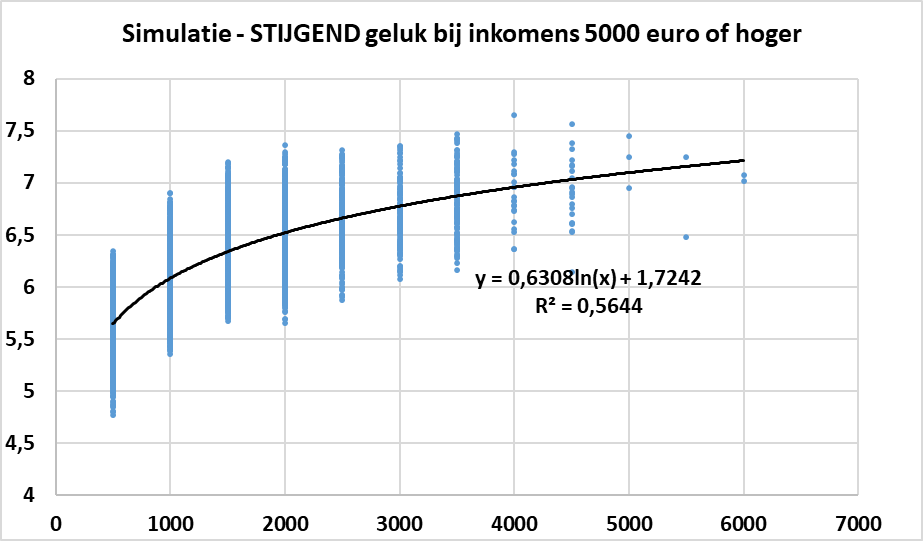
En natuurlijk kan je dit ook met een logaritmische vorm trachten te beschrijven, zoals in onderstaande figuur. De verklaringskracht van de logaritmische functie is -weinig verrassend- ook nu groter dan bij de kwadratische term.
De conclusie is volgens mij duidelijk: op basis van de gegevens die professor Annemans en zijn team verzameld hebben kan je niet zeggen dat de levenstevredenheid daalt bij zeer hoge inkomens.